

協力会社や物品購入で受け取る見積書、無料でCSVへデータベース化する方法を考えてみました。
取引が多い日は10社分・20社分など、それを手入力すると半日潰れてしまうと思います。
しかも金額の転記ミスというヒューマンエラーは常につきまといます。
ではそこに設備投入できるかといえば、全ての事業者ができるわけではありません。
コードの仕組み(3行で説明)
pdfplumberが罫線を自動認識してセルの値を取り出すfind_col()でヘッダー行から「品目」「単価」などの列番号を特定する- 各行の値を取り出してCSVに保存する(合計行・空行は自動スキップ)
 つかだ
つかだ会社ごとに異なる書式に対応できるコードづくりにしました!PDFによってヘッダー名が違っても、HINMOKU_KEYS などのリストにキーワードを追加するだけで対応できます!
こんな方に向けて書いています
- 建設・設備・不動産会社で積算・原価管理・発注管理をしている
- 協力業者・下請けからもらうPDFの単価を台帳や見積比較表に転記する作業がある
- 見積書のデータベース化を無料でしたい
- Pythonは詳しくないが、コピペして動かすくらいはできる
最初に確認:対応しているPDFの種類
このスクリプトが使えるのは「テキスト埋め込みPDF」に限られます。
| 種類 | 作り方の例 | このスクリプトで読めるか |
|---|---|---|
| テキスト埋め込みPDF | Word・Excel・会計ソフト・建設ソフトから「PDF保存」したもの | ✅ 読める |
| スキャン画像PDF | 紙をコピー機でスキャンしたもの | ❌ 読めない |
準備:ライブラリのインストール
Pythonがまだインストールされていない方は、Python公式サイトから 3.10 以上をダウンロードしてインストールしてください。インストール時に「Add Python to PATH」のチェックを必ず入れることを忘れずに。
動作確認環境
| ライブラリ | バージョン |
|---|---|
| Python | 3.13.5 |
| pdfplumber | 0.11.9 |
| pandas | 3.0.2 |
| Windows | 11 |
ライブラリのインストール
pip install pdfplumber pandaspdfplumberで見積書をデータベース化する
PDF内の表のリスト格納
pdfplumberへ取得したい見積書PDFを読ませます。
下記のコードでは、まずリストtablesにPDF内全ての表を格納します。
import pdfplumber
# ── PDFの指定と表取得 ──────────────────────────────────────────────────────
pdf_path = "見積書.pdf" # 取得したいPDFのパス
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages: # 1ページごとループ処理
tables = page.extract_tables() # ← ここでページ内の表を認識し、リストtablesへ格納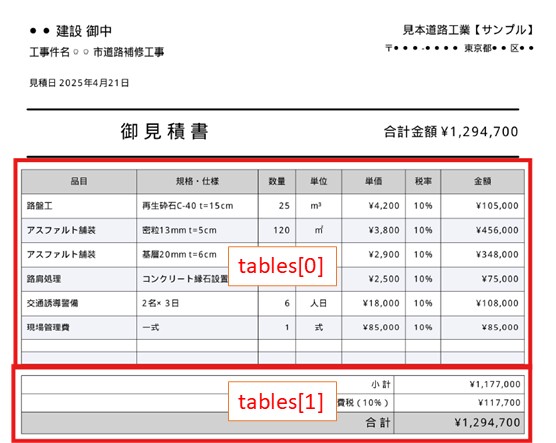
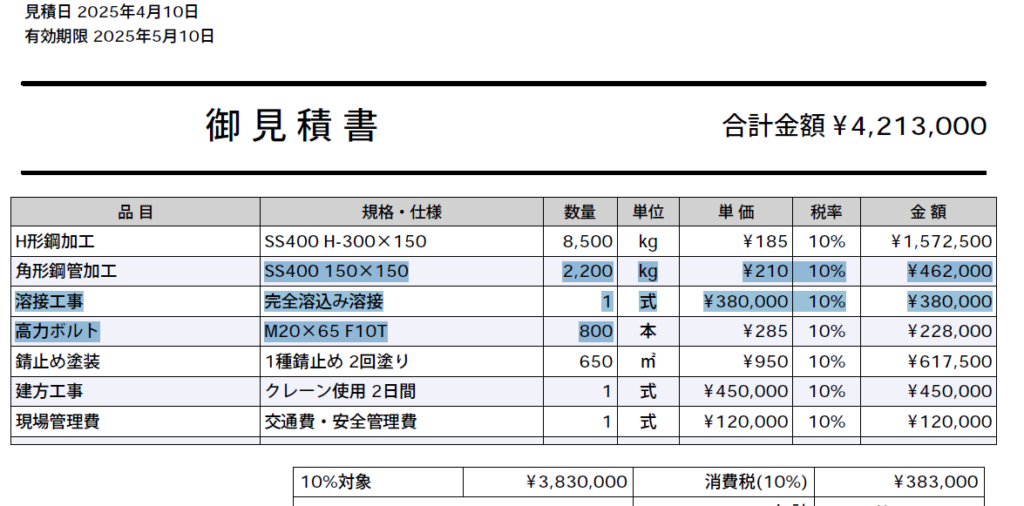
このサンプル見積書の場合、リストtablesへ2種類の表が格納されます。
見積もり内訳の書式を満たす表を特定する
リストtablesには、上記のようなPDFでは表の情報が複数含まれます。
この取得した表情報のどれが目的の見積り内訳の表なのかを判別する必要があります。
# ── 表特定の判定基準と取得項目の設定 ──────────────────────────────────────────────────────
HINMOKU_KEYS = ["品目", "品名", "工種", "工事名", "item"] #ヘッダー品目列の判別基準
TANKA_KEYS = ["単価", "unit price"] #ヘッダー単価列の判別基準
KIKAKU_KEYS = ["規格", "仕様", "型番", "spec"] #ヘッダー規格列の判別基準
TANI_KEYS = ["単位", "unit"] #ヘッダー単位列の判別基準
SURYO_KEYS = ["数量", "qty", "quantity"] #ヘッダー数量列の判別基準
# ── ヘッダーの取得と見積り書式の判定 ──────────────────────────────────────────────────────
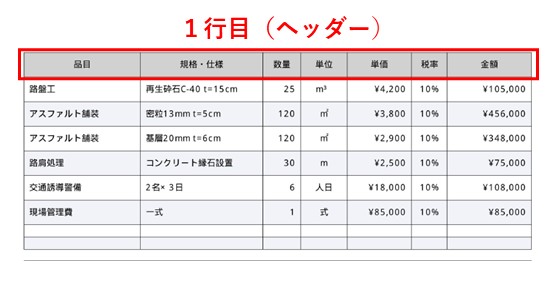
for table in tables:
header = table[0] # 表の一行目 ヘッダーのみリストで取り出す
hi = find_col(header, HINMOKU_KEYS) # HINMOKU_KEYSに該当する値があれば、列数を格納
ti = find_col(header, TANKA_KEYS) # TANKA_KEYSに該当する値があれば、列数を格納
ki = find_col(header, KIKAKU_KEYS) # KIKAKU_KEYS
ui = find_col(header, TANI_KEYS) # TANI_KEYS
si = find_col(header, SURYO_KEYS) # SURYO_KEYS
if hi is None or ti is None: # hiまたはtiに何も格納されていなければ、見積もり内訳ではないと判断
continue # 次のtableへ、ここにひっかかからなければ見積り内訳と判断し次のコードへこの段階で、見積り内訳の表を特定する事は完了しています。
上図と同じ並びでtableリスト内に2次元リスト形式で各セルの文字列が格納されており、
アウトプットする順番がこのままで良ければ、これをcsvとして完了とすることも出来ます。
つかだカスタム性を重視したコードになったと思います😅
他に取得したい要素があれば、判定基準や取得する値を設定すると自由にカスタムできます!
見積り内訳から内容をリストで取り出す
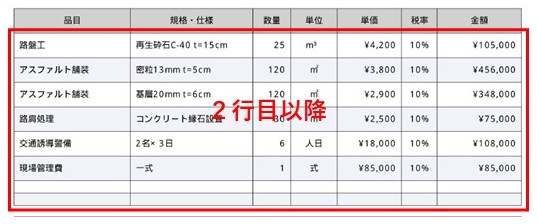
見積り内訳の表リストを特定したら、その表の2行目から行ごとに値を希望の列の順番に並び替えて統一した書式のリストに編纂します。
rows = [] # csv化する値を格納する空リストの宣言
# ── 見積り内訳表の内訳の取得 ──────────────────────────────────────────────────────
for row in table[1:]: # 表の2行目以降(データ行)をループ
hinmoku = row[hi] # 品目列の値 hiには「品目」「品名」などのヘッダーの列数
tanka = row[ti] # 単価列の値
kikaku = row[ki] # 規格列の値
tani = row[ui] # 単位列の値
suryo = row[si] # 数量列の値
# ── 品名が空欄の行や合計行だった場合(表の終わりの認識) ──────────────────────────────────────────────────────
if not hinmoku or hinmoku in ("", "None"): # 品目が空欄の場合表の取得を終了
continue
if any(kw in hinmoku for kw in ["小計", "合計", "消費税"]): # 品目が合計行の場合表の取得を終了
continue
# ── 見積り内訳表の内訳の取得 ──────────────────────────────────────────────────────
# 品目が上記以外の文字列だった場合、取得した値を2次元リストに格納する
rows.append({
"品目": re.sub(r"\s+", "", hinmoku),
"規格": kikaku,
"数量": suryo,
"単位": tani,
"単価": tanka.replace("\\", "¥"),
})
result = pd.DataFrame(rows) # 辞書のリストを表形式に変換
result.to_csv("tanka_output.csv", # CSVファイルに保存
index=False, # 行番号は不要
encoding="utf-8-sig") # Excelで開いたとき文字化けしない形式
rowsは下記のような辞書を内包したリストになります。
[
{“品目”: “路盤工”, “規格”: “再生砕石C-40”, “数量”: “25”, “単位”: “m³”, “単価”: “¥4,200”},
{“品目”: “アスファルト”, “規格”: “密粒13mm”, “数量”: “120”,”単位”: “㎡”, “単価”: “¥3,800”},
{“品目”: “路肩処理”, “規格”: “縁石設置”, “数量”: “30”, “単位”: “m”, “単価”: “¥2,500”}
]
tanka_output.csvでは下記のようなデータが格納されます。
| 品目 | 規格 | 数量 | 単位 | 単価 |
|---|---|---|---|---|
| 路盤工 | 再生砕石C-40 | 25 | m³ | ¥4,200 |
| アスファルト | 密粒13mm | 120 | ㎡ | ¥3,800 |
| 路肩処理 | 縁石設置 | 30 | m | ¥2,500 |
つかだ見積りの内訳をデータベース化できました。
最近は物価高騰も激しいので、特定の製品の価格情報を時系列に整理などの利用ができると思います!
実際の実行結果
5種類の見積書PDF(道路・解体・設備機器・造園・塗装)で実行し、これらを1つのCSVとして保存してみました。PDFが格納された1つのフォルダから連続取得するように設定を変更しています。
| 品目 | 規格 | 数量 | 単位 | 単価 |
|---|---|---|---|---|
| 路盤工 | 再生砕石C-40 t=15cm | 25 | m³ | ¥4,200 |
| アスファルト舗装 | 密粒13mm t=5cm | 120 | ㎡ | ¥3,800 |
| H形鋼加工 | SS400 H-300×150 | 8,500 | kg | ¥185 |
| 溶接工事 | 完全溶込み溶接 | 1 | 式 | ¥380,000 |
| コンセント増設 | 2口 接地付き | 12 | 箇所 | ¥8,500 |
| フローリング | 複合フロア 12mm t | 75 | ㎡ | ¥8,500 |
つかだサンプル見積りは内訳ではない表を他種含ませて見ました。また、列も入れ替えたデータで実験しました。
結果、表のヘッダーを認識して正確に見積り内訳表を特定し、こちらの希望する順番に整列することが出来ていました!
うまくいかないときのチェックリスト
紙の見積書やスキャンPDFが届いた場合は?
「テキスト埋め込みで送ってほしい」と取引先にお願いするのが一番の解決策です。
どうしてもスキャンPDFしかない場合はOCR(文字認識)を組み合わせる方法もありますが、㎡・m³・人日など建設業特有の単位記号が正確に読み取れないことが多く、精度に限界があります。
つかだ筆者が実際に検証した結果、単位列の正解率は最善の条件でも30%前後でした。「㎡」「kg」などの建設業頻出の環境依存記号がOCRはうまく認識出来ませんでした。
実は最初こちらの検証をしていたのですが、実用性の点から文字埋め込み版の記事に切り替えました😅
まとめ
- m³・㎡・人日・セット・箇所もすべて正確に取得
- ヘッダー名が違う書式にもキーワード追加で対応可能
- 異なる取引先の書式を共通のフォーマットでcsv化でき、他の分析ソフトに共有しやすい
高性能のOCRソフトやOCRつきスキャナーなどが出てきていますが、規模の大きくない事業に導入するにはコスパが悪いというイメージです。
このプログラムはPDF読み取り先をフォルダに設定し、格納PDFを一括でCSV化させ、溜まった見積書を一括でCSVにすることもできます!
つかだPDFをフォルダ格納→ソフトを起動→csv化というのは有料ソフトと同じ操作です。浮いたコストと時間で付加価値ある業務に専念できます!
もしご興味ある方がいましたら、是非お知らせください!
コメントお待ちしてます!